Integrating Confluence with Azure OpenAI for Seamless Updates
This Blog post will tell you how easy it will be to integrate external data into Copilot in a quick way, with... maybe low code.
The problem.
A complex Project with multiple information streams, BUT streamlined in one system called confluence from Atlassian. Nice tool, but I wanted to get the latest information on what happened in the project to stay up to date.
So I tried to figure out how I can find a good way to get a solution for this, that will fit all of my colleagues.
The Source
So the source is several pages in confluent. Like meeting minutes. Documentation about processes, and some information about vacation and stuff.
Adding Data to Azure Openai
So at first, we must get the data into a storage that can be easily accessed via the search open ai. So that we can add this as external data. You can use a high-cost connector, but you can work around this wit a small script like this
import requests
from requests.auth import HTTPBasicAuth
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient
import json
import os
# Confluence API Details
confluence_base_url = 'https://DOMAIN.atlassian.net/wiki/rest/api/content'
parent_page_id = 'ROOTPAGEID'
auth = HTTPBasicAuth('EMAILADRESS', 'APITOKEN')
# Azure Blob Storage Details
azure_connection_string = 'YOURCONNECTIONSTRING'
container_name = 'YOURTARGETCONTAINERNAME'
# Initialize Blob Service Client
blob_service_client = BlobServiceClient.from_connection_string(azure_connection_string)
container_client = blob_service_client.get_container_client(container_name)
# Create container if it doesn't exist
try:
container_client.create_container()
except Exception as e:
print(f"Container already exists or could not be created: {e}")
# Function to upload content to Azure Blob Storage
def upload_to_azure_blob(content, blob_name,metadata):
try:
blob_client = container_client.get_blob_client(blob_name)
blob_client.upload_blob(content, overwrite=True)
blob_client.set_blob_metadata(metadata)
print(f"Uploaded {blob_name} to Azure Blob Storage.")
except Exception as e:
print(f"Failed to upload {blob_name}: {e}")
# Function to get child pages
def get_child_pages(parent_id):
url = f"{confluence_base_url}/{parent_id}/child/page"
response = requests.get(url, auth=auth)
response.raise_for_status() # Raise an exception for HTTP errors
return response.json()['results']
# Function to get page content
def get_page_content(page_id):
url = f"{confluence_base_url}/{page_id}"
params = {'expand': 'body.storage,version'}
response = requests.get(url, auth=auth, params=params)
response.raise_for_status() # Raise an exception for HTTP errors
data = response.json()
title = data['title']
body_content = data['body']['storage']['value']
created_date = data['version']['when']
return title, body_content, created_date
# Recursive function to process pages
def process_page(page_id, path=''):
try:
# Get page content
title, content,created_date = get_page_content(page_id)
# Define blob name based on path and title
blob_name = os.path.join(path, f"{title}.html").replace("\\", "/")
metadata = {'created_date': created_date}
# Upload content to Azure Blob Storage
upload_to_azure_blob(content, blob_name,metadata)
# Get child pages and process them recursively
child_pages = get_child_pages(page_id)
for child in child_pages:
process_page(child['id'], os.path.join(path, title))
except Exception as e:
print(f"An error occurred: {e}")
# Main script
if __name__ == "__main__":
process_page(parent_page_id)
This script will navigate recursive through each page and save this as an HTML page. It then will upload it into the Blob storage and add a create date metadata to this.
Before you can run this script, you must add some parameters at the top
confluence_base_url = 'https://DOMAIN.atlassian.net/wiki/rest/api/content'
parent_page_id = 'ROOTPAGEID'
auth = HTTPBasicAuth('EMAILADRESS', 'APITOKEN')
# Azure Blob Storage Details
azure_connection_string = 'YOURCONNECTIONSTRING'
container_name = 'YOURTARGETCONTAINERNAME'
The Email address is the same address that you will use for login to confluence. You must create an API token to access this. You can create it in your settings and security area of your profile page. Last but not least you must provide the connection string to your storage account and the storage name in which the data will be stored. This container will be created if it does not exist.
Setup Azure Open AI
Now that we have the data stored in a blob storage, we can set up Azure open ai.
Please keep in mind, that you may request access to this part in Azure.
The first step is to create a Hub. Microsoft description:
Hubs are the primary top-level Azure resource for AI studio and provide a central way for a team to govern security, connectivity, and computing resources across playgrounds and projects. Once a hub is created, it is enables developers to self-service create projects and access shared company resources without needing an IT administrator's repeated help.
So a Hub is like a resource group in Azure ;). So create a Hub you must open up the Azure openai studio. After that, you navigate on the left side of the navigation to Chat
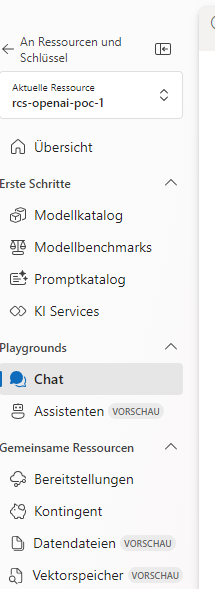
This will open up the chat playground on the left side on this playground you will see the possibility to adjust the prompting like setting the context, also setting parameters (e.g. how many messages in the past must be recognized). Last but not least the data source setting:
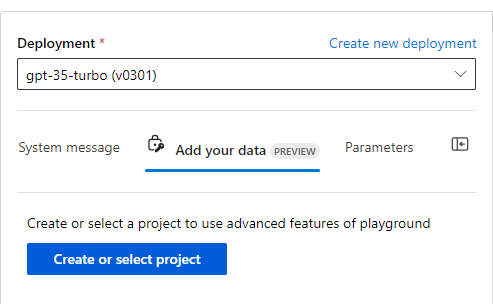
This blog will not describe the deployment of a model, but please keep in mind, that you must do this. This is done by a small wizard at the bottom of the deployment selection.
So next, we create a new project; this will open up the following dialog:
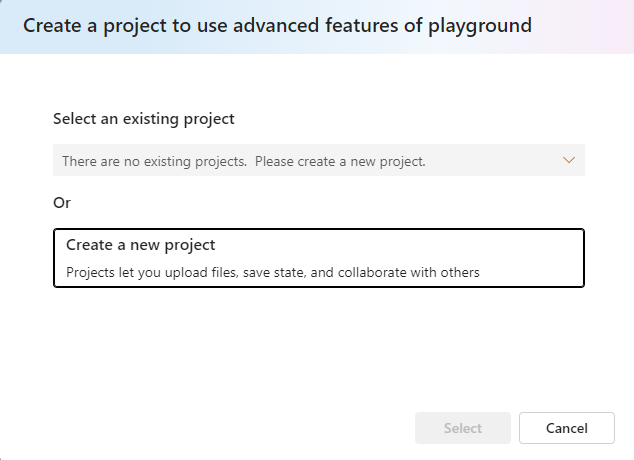
We don't have an existing project, so we click on "Create new project." It opens up a wizard. That will create first a hub and a project:
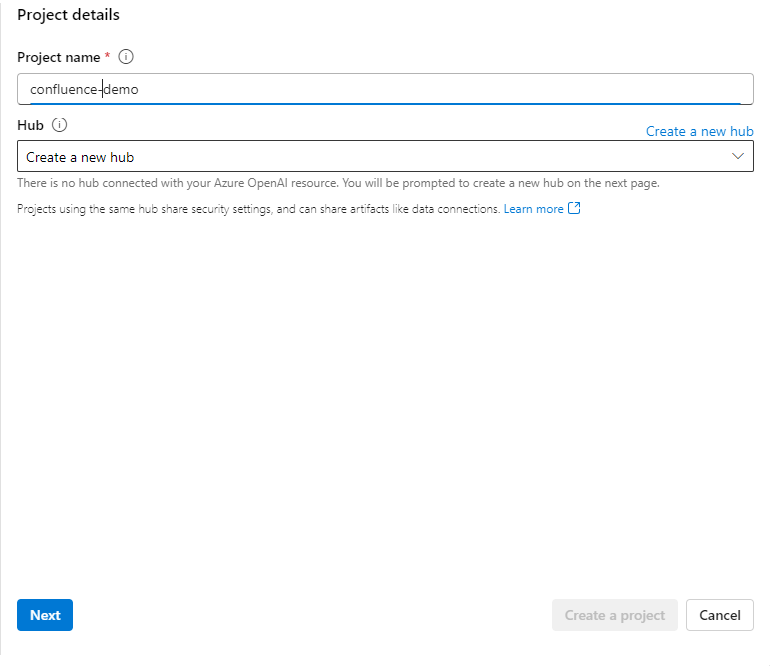
The first step is to create a name for the project. I use the name confluence-demo. The next step is to set up the hub. The hub will combine all things together.
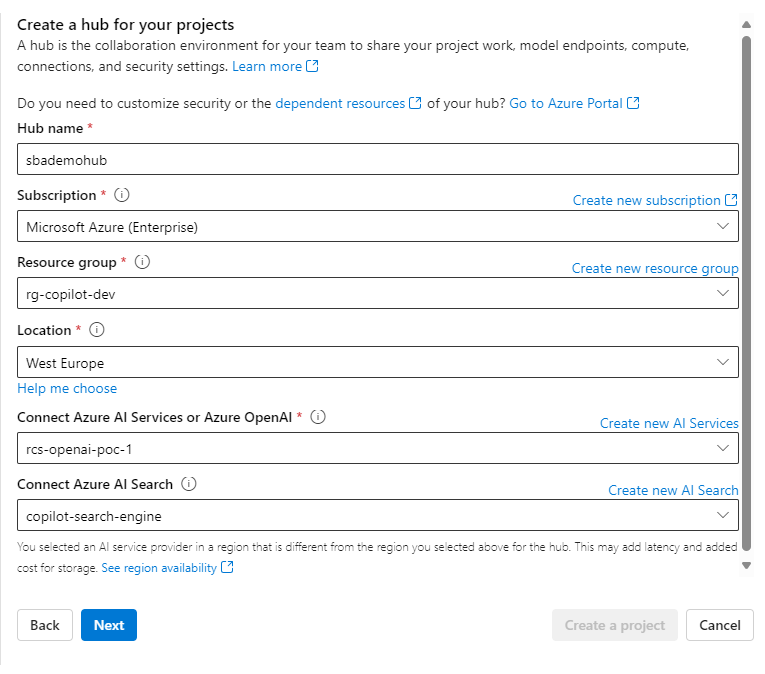
So this hub will be included in the resource group "rg-copilot-dev" in west-Europe. It will reference the created open AI services and an Azure AI search. You will be able to develop it with the desired create actions easily. So grab some coffee.
Because this will create hub resources like a storage account, the key vault, etc.
Small Advice: I won't want to mess up the subscription with many storage accounts, so it is only for demo purposes. You can adjust it to use another account or key vault.
So, we have created a hub and can add custom data to it.
Adding your data to the Azure Open AI
After it is finished creating the resources, the dialog will close, and you can now add the new data source:
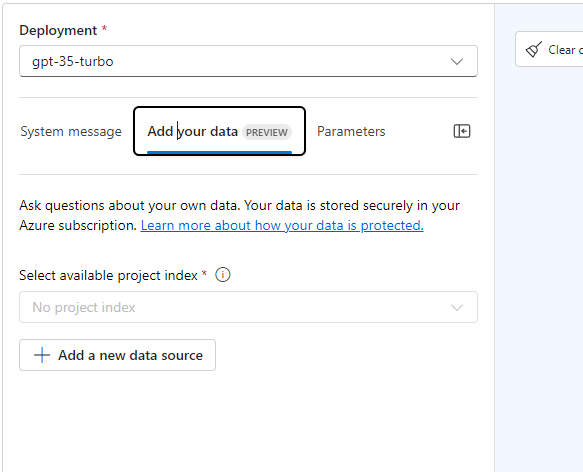
Just click on Add a new data source. We stored our data in a blob storage, so we are selecting this now.
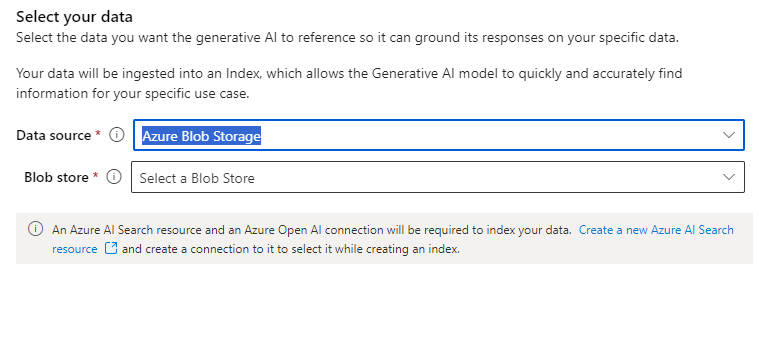
Next, you can select your blob store. You must set up the connection if it does not exist on the list. For this, you can use the desired wizard (please keep in mind that you must at least have read and list access):
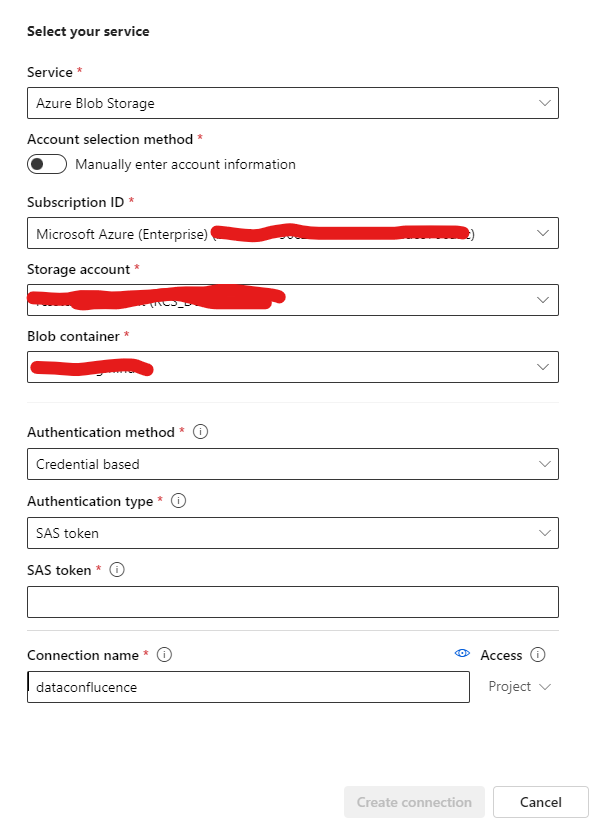
If you add the connection and select it in the first dialog, you will see the containing data:
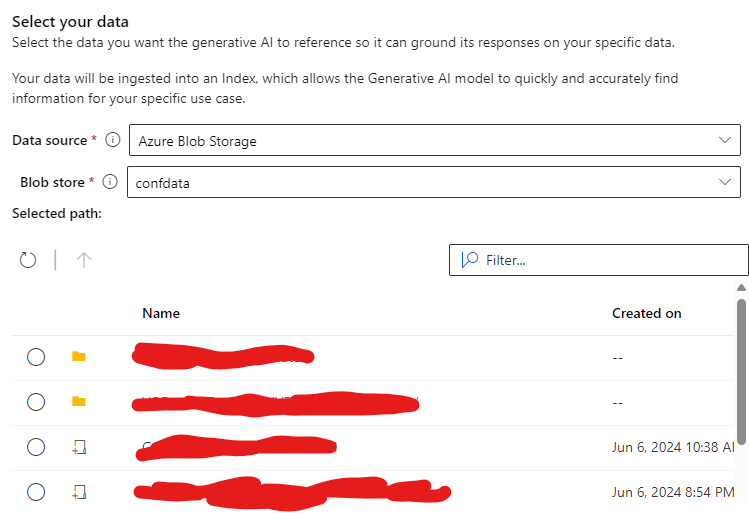
Now, you must select the path to use for the input data. You can now proceed to the next step to configure the index setting:
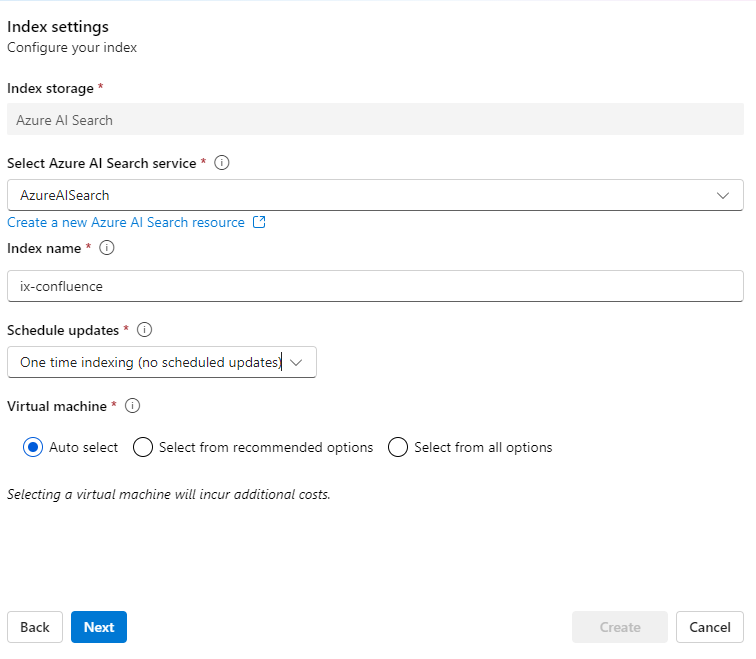
Please adjust your indexing schedule. I use one-time indexing for demo purposes. Next, you can add a vector index.
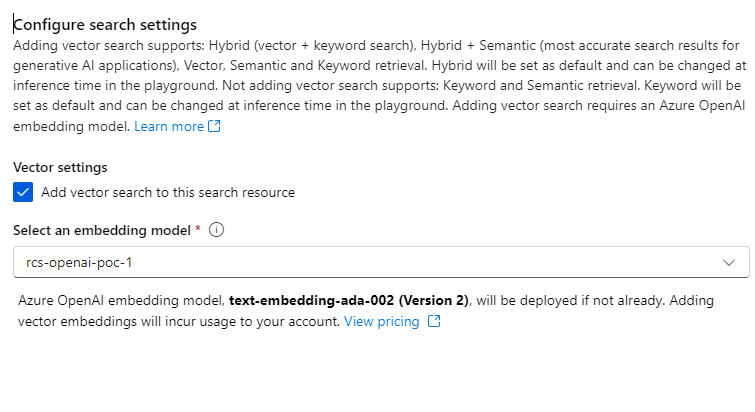
So, it is better to use a vector index because building a little dependency graph will give you a more specific result...
Finally, you can create the datasource. The dialog will close, and the resources will be created. This will take a while.
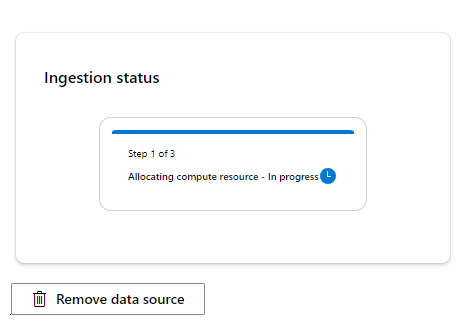
Now It's done! You can now use your own Confluence data. That will (when it is configured) be indexed frequently, and you will be able to use it within your project to query informational data.
Here is an example result:
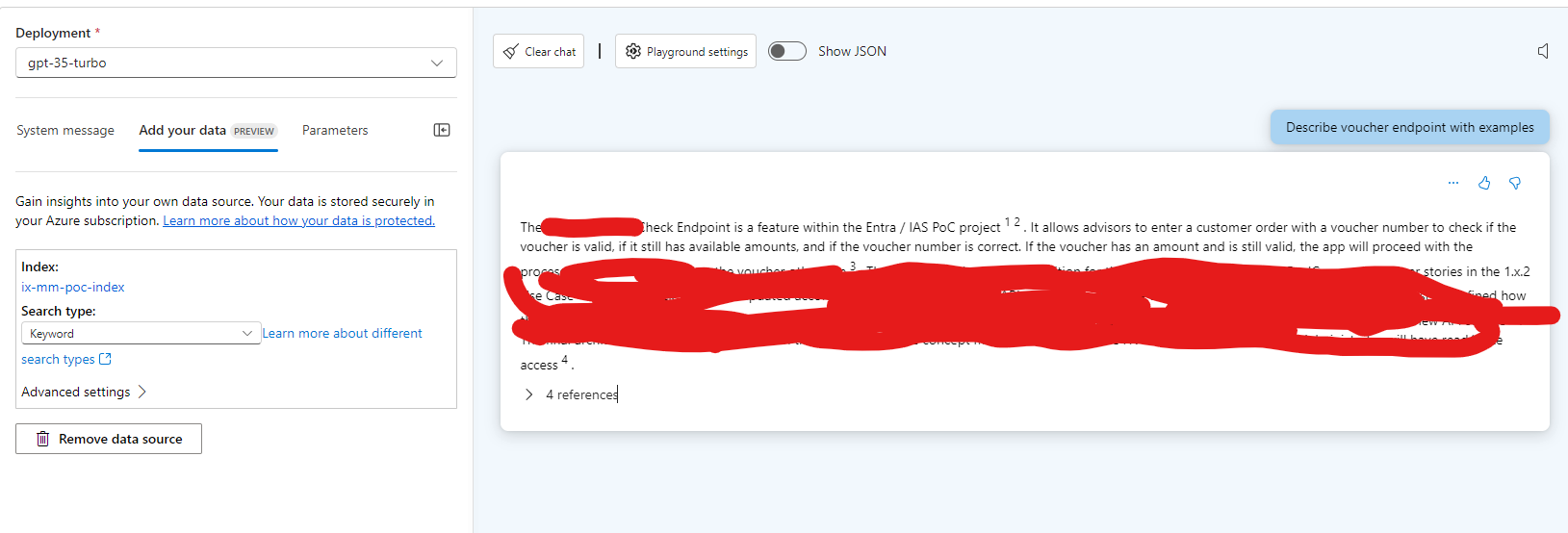
The best thing about this is that you are not limited to Confluence for now; you can add more data from Jira or SharePoint, too. So, you get a big data pool for your project or knowledge space. That can be used as a "big brain," and the AI combined with the search and a good vector database will then be a good sparing partner to bring the data together.
Final Words
Finally, I think that is a good solution for bringing all information together in one particular space. The best thing is that the AI will then analyze and combine the data together (due to the vectorizing). This example solution will be useful in larger projects with many meeting notes/minutes and project documentation spread across a variety of systems.